Simple RNA-Seq pipeline
Overview
Teaching: 20 min
Exercises: 40 minQuestions
How can I create a Nextflow pipeline from a series of unix commands and input data?
How do I log my pipelines parameters?
How can I manage my pipeline software requirement?
How do I know when my pipeline has finished?
How do I see how much resources my pipeline has used?
Objectives
Create a simple RNA-Seq pipeline.
Use the
log.infofunction to print all the pipeline parameters.Print a confirmation message when the pipeline completes.
Use a conda
environment.ymlfile to install the pipeline’s software requirement.Produce an execution report and generates run metrics from a pipeline run.
We are finally ready to implement a simple RNA-Seq pipeline in Nextflow. This pipeline will have 4 processes that:
- Indexes a transcriptome file.
$ salmon index --threads $task.cpus -t $transcriptome -i index
- Performs quality controls
$ mkdir fastqc_<sample_id>_logs
$ fastqc -o fastqc_<sample_id>_logs -f fastq -q <reads>
- Performs transcript level quantification.
$ salmon quant --threads <cpus> --libType=U -i <index> -1 <read1> -2 <read2> -o <pair_id>
- Create a MultiqQC report from the FastQC and salmon results.
$ multiqc .
To start move to scripts/rnaseq_pipeline folder.
$ cd scripts/rnaseq_pipeline
This folder contains files we will be modifying in this episode.
We will also create a symbolic link to the data directory.
$ ln -s ../../data data
Define the pipeline parameters
The first thing we want to do when writing a pipeline is define the pipeline parameters.
The script script1.nf defines the pipeline input parameters.
//script1.nf
params.reads = "$projectDir/data/yeast/reads/*_{1,2}.fq.gz"
params.transcriptome = "$projectDir/data/yeast/transcriptome/*.fa.gz"
params.multiqc = "$projectDir/multiqc"
println "reads: $params.reads"
Run it by using the following command:
$ nextflow run script1.nf
Try to specify a different input parameter, for example:
$ nextflow run script1.nf --reads "data/yeast/reads/ref1*_{1,2}.fq.gz"
reads: data/yeast/reads/ref1*_{1,2}.fq.gz
Add parameter
Modify the
script1.nfadding a fourth parameter namedoutdirand set it to a default path that will be used as the pipeline output directory.Solution
params.outdir = "results"
It can be useful to print the pipeline parameters to the screen. This can be done using the log.info command and a multiline string statement. The string method .stripIndent() command is used to remove the indentation on multi-line strings. log.info also saves the output to the log execution file .nextflow.log.
log.info """\
transcriptome: ${params.transcriptome}
"""
.stripIndent()
log.info
Modify the
script1.nfto print all the pipeline parameters by using a singlelog.infocommand and a multiline string statement. See an example here.$ nextflow run script1.nfLook at the output log
.nextflow.log.Solution
log.info """\ R N A S E Q - N F P I P E L I N E =================================== transcriptome: ${params.transcriptome} reads : ${params.reads} outdir : ${params.outdir} """ .stripIndent()$ less .nextflow.log
Recap
In this step you have learned:
-
How to define parameters in your pipeline script.
-
How to pass parameters by using the command line.
-
The use of
$varand${var}variable placeholders. -
How to use multiline strings.
-
How to use
log.infoto print information and save it in the log execution file.
Create a transcriptome index file
Nextflow allows the execution of any command or user script by using a process definition.
For example,
$ salmon index --threads $task.cpus -t $transcriptome -i index
A process is defined by providing three main declarations:
The second example, script2.nf adds,
- The process
INDEXwhich generate a directory with the index of the transcriptome. This process takes one input, a transcriptome file, and emits one output a salmon index directory. - A queue Channel
transcriptome_chtaking the transcriptome file defined in params variableparams.transcriptome. - Finally the script adds a
workflowdefinition block which calls theINDEXprocess using the Channeltranscriptome_chas input.
//script2.nf
nextflow.enable.dsl=2
/*
* pipeline input parameters
*/
params.reads = "$projectDir/data/yeast/reads/*_{1,2}.fq.gz"
params.transcriptome = "$projectDir/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
params.multiqc = "$projectDir/multiqc"
params.outdir = "results"
println """\
R N A S E Q - N F P I P E L I N E
===================================
transcriptome: ${params.transcriptome}
reads : ${params.reads}
outdir : ${params.outdir}
"""
.stripIndent()
/*
* define the `INDEX` process that create a binary index
* given the transcriptome file
*/
process INDEX {
input:
path transcriptome
output:
path 'index'
script:
"""
salmon index --threads $task.cpus -t $transcriptome -i index
"""
}
transcriptome_ch = channel.fromPath(params.transcriptome)
workflow {
INDEX(transcriptome_ch)
}
Try to run it by using the command:
$ nextflow run script2.nf
The execution will fail because Salmon is not installed in your environment.
Add the command line option -profile conda to launch the execution through a conda environment as shown below:
$ nextflow run script2.nf -profile conda
This time it works because it uses the conda environment file environment.yml defined in the nextflow.config file.
//nextflow.config
profiles {
conda {
process.conda = 'environment.yml'
}
}
Enable conda by default
Enable the conda execution by removing the profile block in the
nextflow.configfile.Solution
//nextflow.config file process.conda = 'environment.yml'
Print output of the contents of the index_ch
Print the output of the
index_chchannel by using theviewoperator.Solution
..truncated... workflow { INDEX(transcriptome_ch).view() }
Recap
In this step you have learned:
-
How to define a process executing a custom command
-
How process inputs are declared
-
How process outputs are declared
-
How to use a nextflow configuration file to define and enable a
condaenvironment. -
How to print the content of a channel
view()
Collect read files by pairs
This step shows how to match read files into pairs, so they can be mapped by salmon.
The script script3.nf adds a line to create a channel, read_pairs_ch, containing fastq read pair files using the fromFilePairs channel factory.
//script3.nf
nextflow.enable.dsl = 2
/*
* pipeline input parameters
*/
params.reads = "$projectDir/data/yeast/reads/ref1_{1,2}.fq.gz"
params.transcriptome = "$projectDir/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
params.multiqc = "$projectDir/multiqc"
params.outdir = "results"
log.info """\
R N A S E Q - N F P I P E L I N E
===================================
transcriptome: ${params.transcriptome}
reads : ${params.reads}
outdir : ${params.outdir}
"""
.stripIndent()
read_pairs_ch = Channel.fromFilePairs( params.reads )
Edit the script script3.nf and add the following statement as the last line:
read_pairs_ch.view()
Save it and execute it with the following command:
$ nextflow run script3.nf
It will print an output similar to the one shown below:
[ref1, [data/yeast/reads/ref1_1.fq.gz, data/yeast/reads/ref1_2.fq.gz]]
The above example shows how the read_pairs_ch channel emits tuples composed by two elements, where the first is the read pair prefix and the second is a list representing the actual files.
Try it again specifying different read files by using the glob pattern:
$ nextflow run script3.nf --reads 'data/yeast/reads/*_{1,2}.fq.gz'
File paths including one or more wildcards ie. *, ?, etc. MUST be wrapped in single-quoted characters to avoid Bash expanding the glob pattern on the command line.
setoperatorUse the
setoperator in place of = assignment to define the read_pairs_ch channel.Solution
Channel.fromFilePairs(params.reads) .set{read_pairs_ch}
checkIfExists
Use the
checkIfExistsoption for thefromFilePairsmethod to check if the specified path contains at least file pairs.Solution
Channel.fromFilePairs(params.reads, checkIfExists: true) .set{read_pairs_ch}
Recap
In this step you have learned:
-
How to use
fromFilePairsto handle read pair files -
How to use the
checkIfExistsoption to check input file existence -
How to use the
setoperator to define a new channel variable
Perform expression quantification
The script script4.nf adds the quantification process, QUANT.
//script4.nf
..truncated..
/*
* Run Salmon to perform the quantification of expression using
* the index and the matched read files
*/
process QUANT {
input:
path index
tuple val(pair_id), path(reads)
output:
path(pair_id)
script:
"""
salmon quant --threads $task.cpus --libType=U -i $index -1 ${reads[0]} -2 ${reads[1]} -o $pair_id
"""
}
..truncated..
workflow {
index_ch=INDEX(params.transcriptome)
quant_ch=QUANT(index_ch,read_pairs_ch)
}
In this script the index_ch channel, declared as output in the INDEX process, is used as the first input argument to the QUANT process.
The second input argument of the QUANT process, the read_pairs_ch channel, is a tuple composed of two elements: the pair_id and the reads.
Execute it by using the following command:
$ nextflow run script4.nf
You will see the execution of the index and quantification process.
Re-run the command using the -resume option
$ nextflow run script4.nf -resume
The -resume option cause the execution of any step that has been already processed to be skipped.
Try to execute it with more read files as shown below:
$ nextflow run script4.nf -resume --reads 'data/yeast/reads/*_{1,2}.fq.gz'
You will notice that the INDEX step and one of the QUANT steps has been cached, and
the quantification process is executed more than one time.
When your input channel contains multiple data items Nextflow parallelises the execution of your pipeline.
Add a tag directive
Add a
tagdirective to theQUANTprocess ofscript4.nfto provide a more readable execution log.Solution
tag "quantification on $pair_id"
Add a publishDir directive
Add a
publishDirdirective to the quantification process ofscript4.nfto store the process results into folder specified by theparams.outdirNextflow variable. Include thepublishDirmodeoption to copy the output.Solution
publishDir "${params.outdir}/quant", mode:'copy'
Recap
In this step you have learned:
-
How to connect two processes by using the channel declarations
-
How to resume the script execution skipping already computed tasks
-
How to use the
tagdirective to provide a more readable execution output -
How to use the
publishDirto store a process results in a path of your choice
Quality control
This step implements a quality control step for your input reads. The input to the FASTQC process is the same read_pairs_ch that is provided as input to the quantification process QUANT .
//script5.nf
[..truncated..]
/*
* Run fastQC to check quality of reads files
*/
process FASTQC {
tag "FASTQC on $sample_id"
cpus 1
input:
tuple val(sample_id), path(reads)
output:
path("fastqc_${sample_id}_logs")
script:
"""
mkdir fastqc_${sample_id}_logs
fastqc -o fastqc_${sample_id}_logs -f fastq -q ${reads} -t ${task.cpus}
"""
}
[..truncated..]
workflow {
index_ch=INDEX(params.transcriptome)
quant_ch=QUANT(index_ch,read_pairs_ch)
}
Run the script script5.nf by using the following command:
$ nextflow run script5.nf -resume
The FASTQC process will not run as the process has not been declared in the workflow scope.
Add FASTQC process
Add the
FASTQCprocess to theworkflow scopeofscript5.nfadding theread_pairs_chchannel as an input. Run the nextflow script using the-resumeoption.$ nextflow run script5.nf -resumeSolution
workflow { index_ch=INDEX(params.transcriptome) quant_ch=QUANT(index_ch,read_pairs_ch) fastqc_ch=FASTQC(read_pairs_ch) }
Recap
In this step you have learned:
- How to add a
processto theworkflowscope. - Add a channel as input to a
process.
MultiQC report
This step collects the outputs from the quantification and fastqc steps to create a final report by using the MultiQC tool.
The input for the MULTIQC process requires all data in a single channel element.
Therefore, we will need to combine the FASTQC and QUANT outputs using:
- The combining operator
mix: combines the items in the two channels into a single channel
//example of the mix operator
ch1 = Channel.of(1,2)
ch2 = Channel.of('a')
ch1.mix(ch2).view()
1
2
a
- The transformation operator
collectcollects all the items in the new combined channel into a single item.
//example of the collect operator
ch1 = Channel.of(1,2,3)
ch1.collect().view()
[1, 2, 3]
Combing operators
Which is the correct way to combined
mixandcollectoperators so that you have a single channel with one List item?
quant_ch.mix(fastqc_ch).collect()quant_ch.collect(fastqc_ch).mix()fastqc_ch.mix(quant_ch).collect()fastqc_ch.collect(quant_ch).mix()Solution
You need to use the
mixoperator first to combine the channels followed by thecollectoperator to collect all the items in a single item. Therefore, both 1 and 3 will achieve the behavior we desire for this step.
In script6.nf we use the statement quant_ch.mix(fastqc_ch).collect() to combine and collect the outputs of the QUANT and FASTQC process to
create the required input for the MULTIQC process.
[..truncated..]
//script6.nf
/*
* Create a report using multiQC for the quantification
* and fastqc processes
*/
process MULTIQC {
publishDir "${params.outdir}/multiqc", mode:'copy'
input:
path('*')
output:
path('multiqc_report.html')
script:
"""
multiqc .
"""
}
Channel
.fromFilePairs( params.reads, checkIfExists:true )
.set { read_pairs_ch }
workflow {
index_ch=INDEX(params.transcriptome)
quant_ch=QUANT(index_ch,read_pairs_ch)
fastqc_ch=FASTQC(read_pairs_ch)
MULTIQC(quant_ch.mix(fastqc_ch).collect())
}
Execute the script with the following command:
$ nextflow run script6.nf --reads 'data/yeast/reads/*_{1,2}.fq.gz' -resume
It creates the final report in the results folder in the ${params.outdir}/multiqc directory.
Recap
In this step you have learned:
-
How to collect many outputs to a single input with the
collectoperator -
How to mix two channels in a single channel using the
mixoperator. -
How to chain two or more operators togethers using the
.operator.
Handle completion event
This step shows how to execute an action when the pipeline completes the execution.
Note: Nextflow processes define the execution of asynchronous tasks i.e. they are not executed one after another as they are written in the pipeline script as it would happen in a common imperative programming language.
The script uses the workflow.onComplete event handler to print a confirmation message when the script completes.
workflow.onComplete {
log.info ( workflow.success ? "\nDone! Open the following report in your browser --> $params.outdir/multiqc/multiqc_report.html\n" : "Oops .. something went wrong" )
}
This code uses the ternary operator that is a shortcut expression that is equivalent to an if/else branch assigning some value to a variable.
If expression is true? "set value to a" : "else set value to b"
Try to run it by using the following command:
$ nextflow run script7.nf -resume --reads 'data/yeast/reads/*_{1,2}.fq.gz'
Done! Open the following report in your browser --> results/multiqc/multiqc_report.html
Metrics and reports
Nextflow is able to produce multiple reports and charts providing several runtime metrics and execution information.
-
The
-with-reportoption enables the creation of the workflow execution report. -
The
-with-traceoption enables the creation of a tab separated file containing runtime information for each executed task, including: submission time, start time, completion time, cpu and memory used. -
The
-with-timelineoption enables the creation of the workflow timeline report showing how processes were executed along time. This may be useful to identify most time consuming tasks and bottlenecks. See an example at this link. -
The
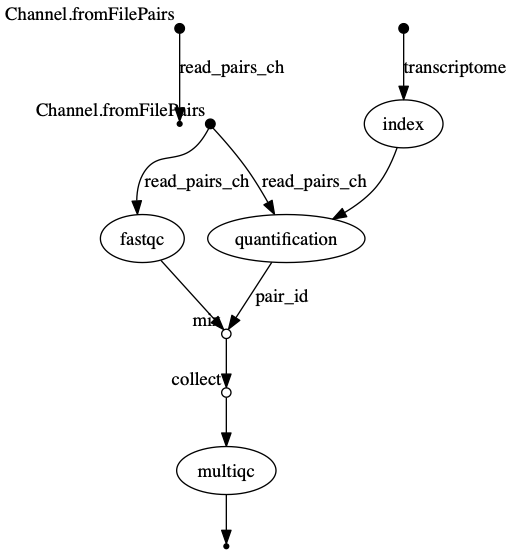
-with-dagoption enables to rendering of the workflow execution direct acyclic graph representation. Note: this feature requires the installation of Graphviz, an open source graph visualization software, in your system.
More information can be found here.
Metrics and reports
Run the script7.nf RNA-seq pipeline as shown below:
$ nextflow run script7.nf -resume -with-report -with-trace -with-timeline -with-dag dag.png
- Open the file
report.htmlwith a browser to see the report created with the above command.- Check the content of the file
trace.txtfor an example.Solution
dag.png
Key Points
Nextflow can combine tasks (processes) and manage data flows using channels into a single pipeline/workflow.
A Workflow can be parameterised using
params. These values of the parameters can be captured in a log file usinglog.infoNextflow can handle a workflow’s software requirements using several technologies including the
condapackage and enviroment manager.Workflow steps are connected via their
inputsandoutputsusingChannels.Intermediate pipeline results can be transformed using Channel
operatorssuch ascombine.Nextflow can execute an action when the pipeline completes the execution using the
workflow.onCompleteevent handler to print a confirmation message.Nextflow is able to produce multiple reports and charts providing several runtime metrics and execution information using the command line options
-with-report,-with-trace,-with-timelineand produce a graph using-with-dag.